PDF Content Extractor
From Appvance IQ it is possible to read a pdf document and is possible to assert for a string in the whole document or you can also mention asserting for content on a specific page of the document. All from Scenario Builder Assertions.
The below example shows an example of how this can be achieved.
A simple java file was created which browses the pdf document and a jar file was created out of the java file.
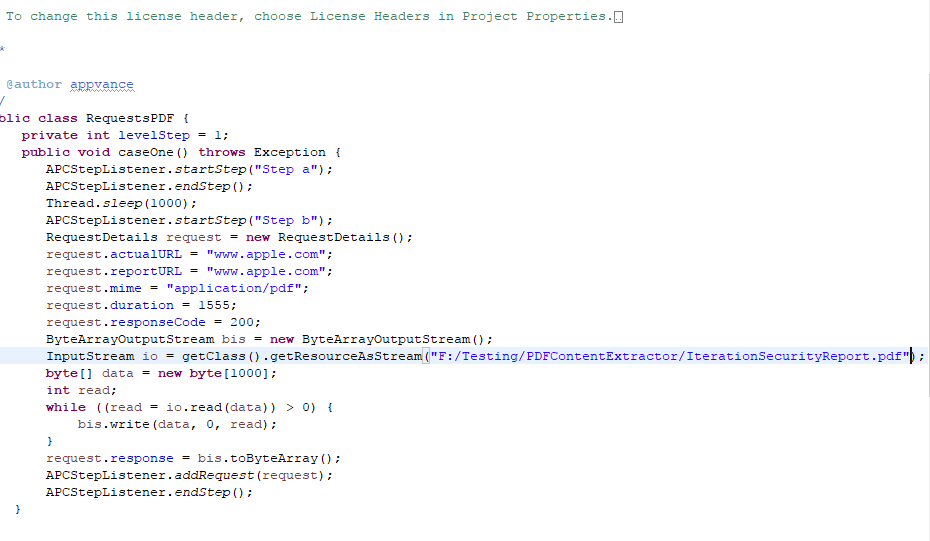
Go to Scenario Builder and create a functional scenario with the script type being 'Java' and provide the Class and the method name as desired and browse the jar file.
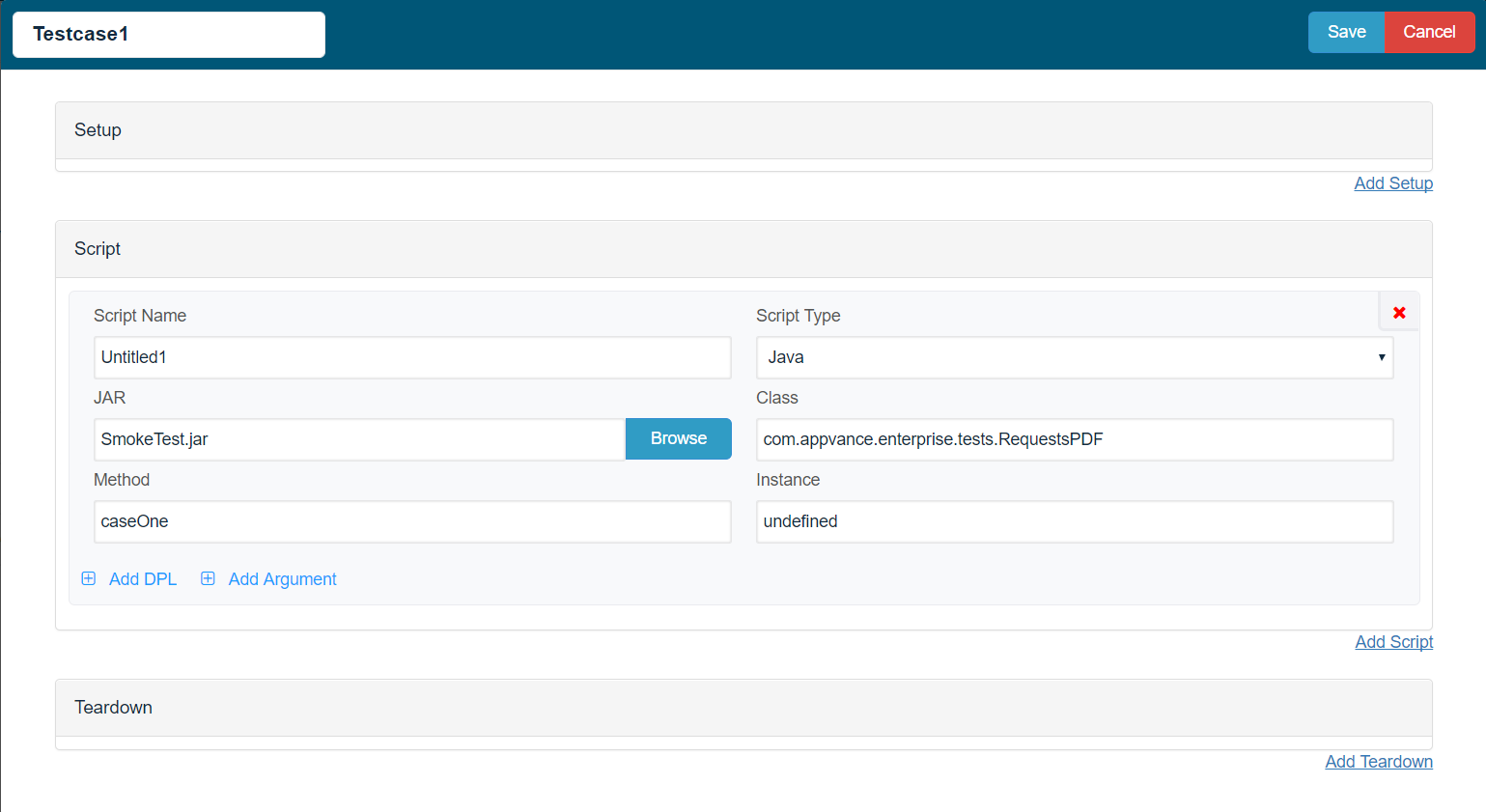
Save the scenario and Play the scenario.
Once the scenario is played back successfully, go to the Validation Suite tab and select the required assertions from the drop-down available.
You can choose the test-case, from the drop-down and also choose the step / Request
And provide the expected Value (Expected text that we are looking for from the PDF), Format can be chosen as PDF and the target can be a
-
Page number
-
A regular expression
-
or the full document itself.
Once those entries and made, from the Scenario Builder, refresh the scenario to have those assertions added. Check the below screenshots for reference.
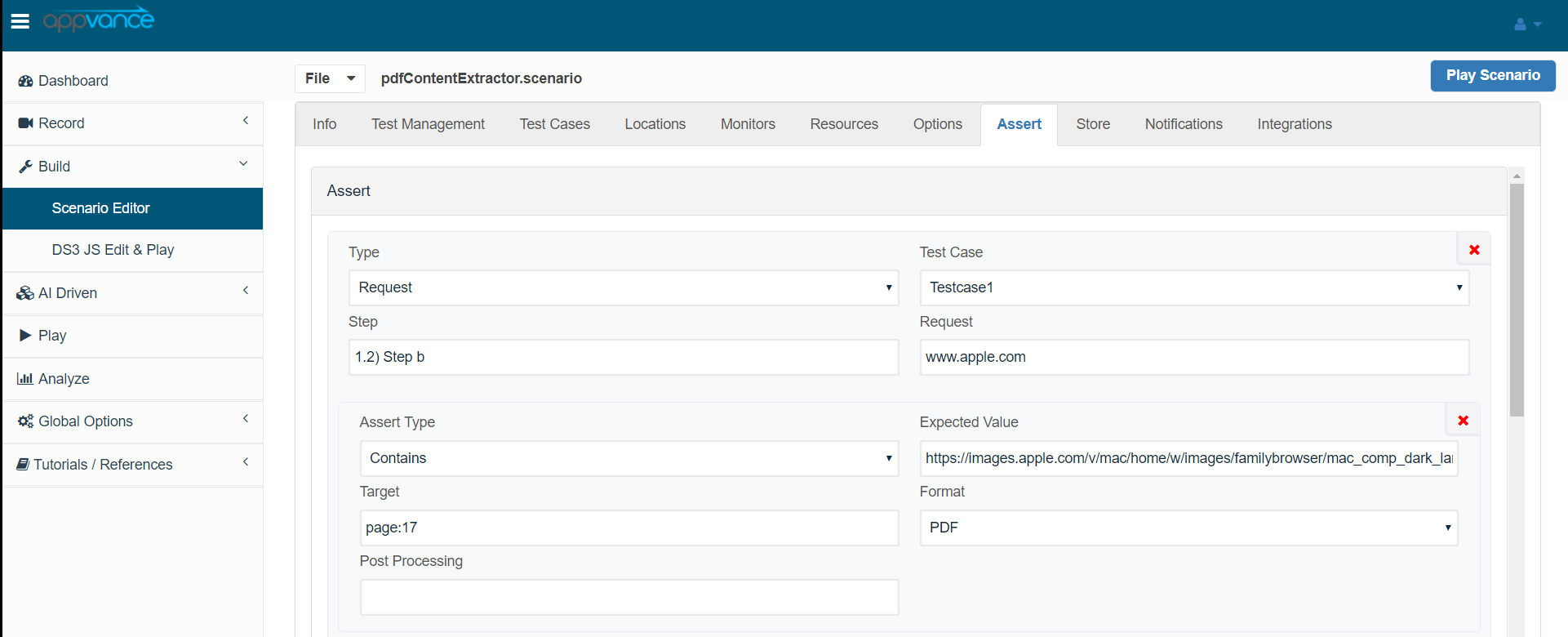
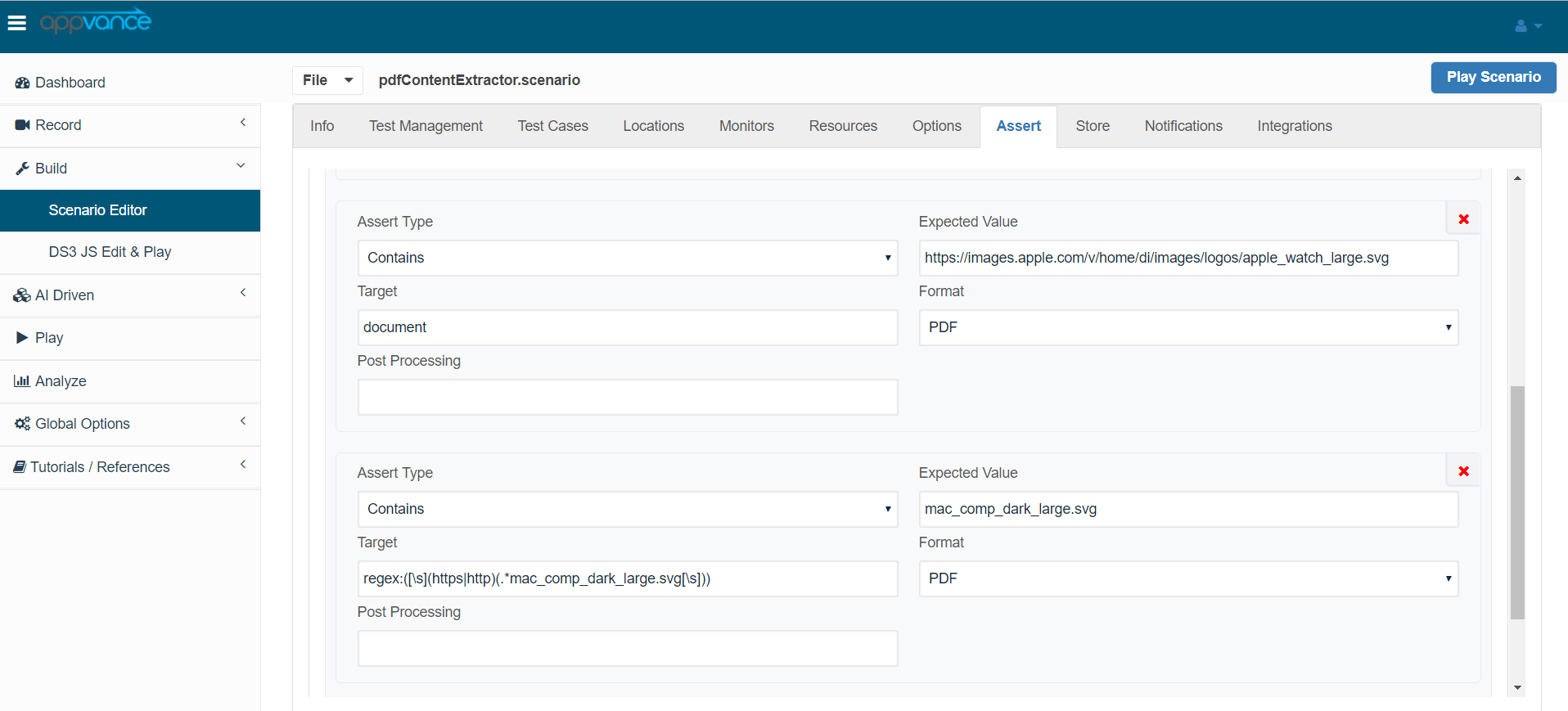
Save the scenario again and playback the scenario to check the results of the pdf validations.